

Recommender systems are not a new phenomenon. Retailers have known for many years, well before the arrival of the Internet, that sales of an item were increased when that item was displayed prominently. As retailing became more sophisticated, retailers learned to make more specific links from one product to another. Today, the same process is used on internet buying sites such as Amazon. For example, a would-be purchaser selects a book about the French Revolution, and sees a page with details of the book, with some “frequently bought together” titles below:

Should all recommendation services be like Amazon? The answer, perhaps not so surprisingly, is that it depends on the context.
If you are buying a Christmas present for your grandmother in a retail trade environment such as Amazon, you may well be interested in Amazon presenting to you snippets from its vast database tracking correlation between purchases of titles. Thus, in the illustration above, customers have in the past shown a preference between buying a guide to the French Revolution and, believe it or not, a history of the Italian Renaissance, and a historical novel by Hilary Mantel set in 16th-century England. But wait a moment! These books have nothing whatever in common with each other – they are set in periods that are hundreds of years apart, for a start. All that they share is that, in the context of a purchase for pleasure, readers buying one of these books have also tended to buy one of the others. These suggestions may be very useful when selecting a gift for your grandmother (“if she liked that, then the chances are she’ll like this...”)
Academic research, however, is fundamentally different to a trade bookshop. Academic researchers are certainly looking for content, but their use case is much more specific. Typically, a researcher will be looking for content on a topic: if the topic is the French Revolution, the researcher will want to see what else has been published on the same topic. The researcher isn’t interested so much in what other researchers have read, or bought, but in what content exists on that subject.
This is where content-based recommendation tools such as UNSILO Recommend become essential. Whereas purchase-based recommendations are subject to serendipity, content-based recommenders enable researchers to carry out a literature search far more effectively than a hand-curated bibliography could. One reason is that the concept extraction tool that forms the basis of UNSILO’s recommender works at a far more granular level than “French Revolution”, or “physics” or “chemistry”. UNSILO extracts over a hundred concepts for each academic journal article or book chapter, and so enables far more precise links to be identified than any manual tagging system. Here, for example, is an example from the Cambridge University Press website, containing over two million articles and book chapters, illustrating a chapter about liver transplantation. The UNSILO-generated recommended content is shown in the right-hand column:
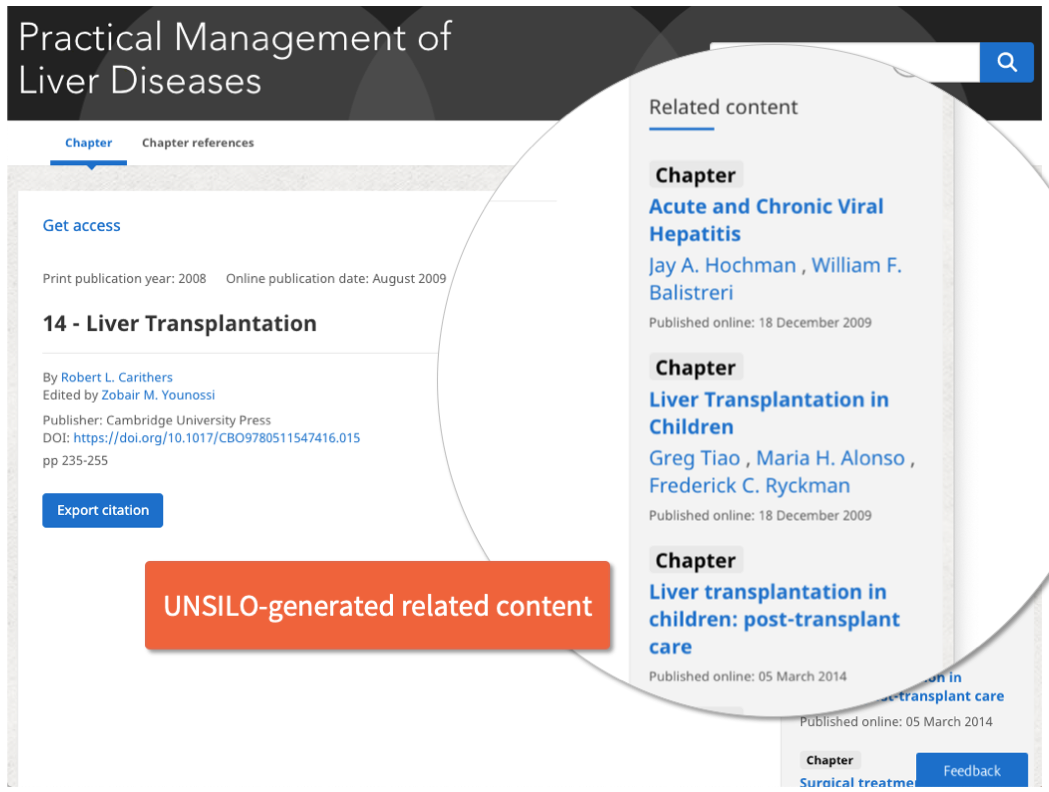
Among the related content is a chapter on hepatitis, a disease of the liver. The UNSILO engine is identifying semantic links between synonyms and closely related phrases, and using a cluster of concepts for every article, identifies the most related content to the selected text. The link between “liver” and “hepatitis” is a semantic one, not a string match. And because the index is updated on a continuous basis, typically every 24 hours, whenever new content is published by Cambridge, the links between chapters, articles, and books is continuously updated. Most importantly, this technology is a powerful example of machine learning: it requires no external taxonomy or ontology to work. The system identifies concepts from each article and chapter, and by an intensive and detailed comparison with all the other content in the corpus, it reveals the distinctive concepts in each content. These concepts are remarkably like a taxonomy, only considerably more granular.
How does this affect Silverchair’s customers? A few years ago, AI-based tools such as UNSILO were only available to the largest publishers with very deep pockets to pay for the extensive cloud-based storage required to match millions of concepts and rank them, article by article. UNSILO’s first customer for recommended links was Springer Nature, with over fifteen million books and journal articles. But using the Silverchair Platform, economies of scale mean that this technology, formerly only for the biggest publishers, can be implemented in a cost-effective way on much smaller collections. Much of the infrastructure is based around common APIs that are very easily configured for the requirements of individual Silverchair customers. As a result, the cost per customer is dramatically lower than building a collection from scratch. Combined with the steady decrease in storage and computing costs means that even small- and mid-size publishers can make use of leading-edge technology.
Recommended articles are delivered via a simple UNSILO API that requires no understanding of AI or machine-learning to implement. The styling is done by the Silverchair team. After the integration is complete, the system generates up-to-date recommendations on a continuous basis.
It is a twenty-first century solution to a nineteenth-century problem.
For more information about using UNSILO to improve connections within your content, reach out to your PDM, or visit www.unsilo.ai.
![]()
![]()
About UNSILO
UNSILO (www.unsilo.ai) is a CACTUS brand that develops advanced AI tools for text understanding and processing. It delivers dramatic workflow improvements by reducing processing time and, at the same time, improving quality and accuracy. CACTUS (cactusglobal.com) is a global scientific communications company that collaborates with researchers across academic disciplines, universities, publishers, societies, and life science organizations to accelerate research impact. CACTUS has offices in London, Princeton, Singapore, Beijing, Shanghai, Tokyo, Seoul, Aarhus, Bengaluru, Hyderabad, and Mumbai; a global workforce of over 1,000 people; and customers from over 190 countries.