

![]()
![]()
In recent years, we have seen the topic of research data increase in importance across all areas of academia. Making research data openly available aids reproducibility, avoids duplication of effort, increases the impact of research funding, and is generally recognized as good scientific practice. With this increased importance of research data across scholarly communication, we have seen a rise in the number of publishers starting to encourage researchers to make their data openly available through data availability policies.
2018 saw open data mature through initiatives to enhance the quality of open data and 2019 has started with a huge win for open data in the US, “a sweeping, government-wide mandate requiring U.S. federal agencies to publish all non-sensitive government information – including federally-funded research – as open data.”
In this post, we’ll reflect on how the open data movement has matured over 2018 and the opportunities it creates for publishers in 2019.
What is FAIR data and why is it important?
The term ‘open data’ can be broadly applied to any data that is made openly available for the public to reuse. This is a great position to start from and infinitely better than data not being shared at all, but for data to be useful for current and future generations there need to be some standards in place.
Thankfully, the research community have established that data should be open and it should also be Findable, Accessible, Interoperable, and Reusable (FAIR). The FAIR Guiding Principles for scientific data management and stewardship, published in Scientific Data, establishes best practice on how to ensure that data is made openly available long-term in a way that is easy for fellow researchers to access and reuse without having to contact the original author.
The FAIR principles have started to be adopted by publishers, institutions and funders as the gold standard aspiration for all open data. At Figshare we develop all of our features with one eye on the FAIR principles to make sure that when researchers deposit their data with us, we do all the technical heavy lifting, leaving researchers to focus on accurate, descriptive, discipline-specific metadata as described in this infographic.
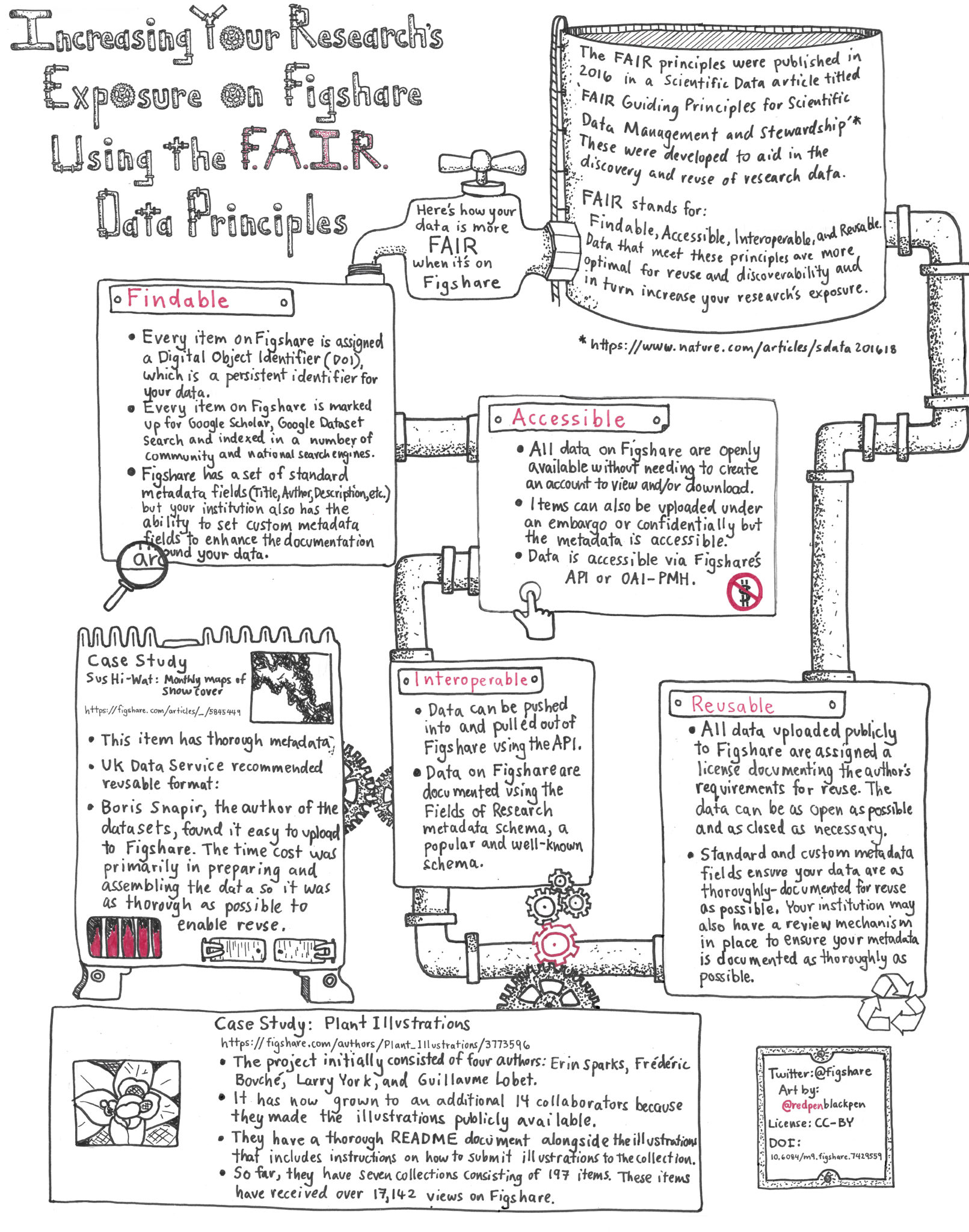
Illustration by Jason McDermott of RedPenBlackPen
The State of Open Data
Since 2016, Figshare, Digital Science, and Springer Nature have partnered to conduct a large scale survey of researchers on their attitudes to open data. This results in the State of Open Data report, which is published every year during Open Access Week in October.

Some key findings from the 2018 report include:
- 64% of respondents revealed they made their data openly available in 2018, a 7% rise on 2016.
- Data citations are motivating more respondents to make data openly available, increasing 7% from 2017 to 46%
- 60% of respondents had never heard of FAIR principles
- The percentage of respondents in support of national mandates for open data is higher at 63% than in 2017 (55%)
- Respondents who revealed that they had reused open data in their research continues to shrink. In 2018 48% said they had done this, whereas in 2017 50% had done so, with 2016 57% in 2016.
- Most researchers felt that that they did not get sufficient credit for sharing data (58%), compared to 9% who felt they do.
- Respondents having lost research data has decreased from 2017 (36%, versus 30% in 2018).
Data Curation Services
A growing number of publishers are now publishing supporting data alongside articles, but as the 2018 State of Open Data showed, there is still some confusion in the research community around best practices for FAIR data and research data management. Publishers have established a reputation as the arbiters of quality for papers and have the opportunity to extend this to data. Whilst data stewards play an important role within institutions, publishers, with their extensive discipline-specific knowledge, can help provide curation services to validate and enrich data. Springer Nature is currently leading the way on this new opportunity with their Research Data Services providing research data support for institutions, research data training, and data availability reporting. This new business model provides a valuable service that taps into the strengths of the researchers, institutions, and publishers, which ultimately improves the quality of data being made available.
With staggering stats on how much data we create daily, the data deluge is set to increase in 2019. This creates huge opportunities for publishers who embrace this new data driven world. By hosting data alongside traditional articles, publishers can encourage better science and improve the quality of data available for current and future researchers.