

In the last decade, we’ve seen repeated reports highlighting a lack of reproducibility and replicability in published academic research results. This has led to institutional, publisher, and, most significantly, funder mandates for research data being made openly available at the point of publication of the paper.
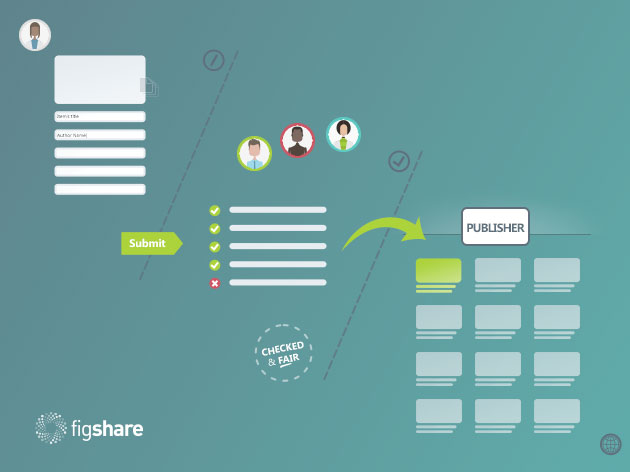
Over 10 years, we have seen a groundswell of these policies and mandates. This has led to large amounts of data files with associated metadata being made available in many data repositories around the world. The birth of the concept of FAIR (Findable, Accessible, Interoperable, Reusable) data in 2014 (1) has helped unite global initiatives with a broad, common goal. We have even been hearing from researchers themselves that this is a change they want (2). Doing your research becomes so much easier when you can build on top of the raw research that has gone before and not just the summarized findings in the form of a conclusions section of a peer reviewed article.
So, what are the next steps in ensuring all of this information can be turned into knowledge consumable by fellow researchers and AI models?
Several recent, high-profile publications have highlighted some of these problems (3). As data publishing becomes the norm, questions are surfacing about who should be responsible for checking these datasets and their associated metadata and to what level they should be examining the research. One of the goals of FAIR is to allow researchers to take published data, understand it, and build on top of it without ever needing to contact the original author.
Publishers stand in a unique position to help in guiding researchers to ensure their data is as well described as possible at the point of publication.
The following seven steps are what we at Figshare believe publishers should be aiming toward, starting with basic checks and moving on to the more complex.
- The data and metadata are published in an online repository that follows best practice norms
- The metadata has a descriptive title sufficient enough to make it discoverable through a Google search
- The files are under the correct license, have no personal identifiable information, and comply with applicable policies
- Files are in an open, preservation-optimized format
- Subject-specific metadata schemas are applied in compliance with community best practices
- Forensic data checks are run to ensure the data are not edited or augmented
- The results and re-run to ensure replicability
The research data community needs to come up with a plan to move to fully FAIR data (points 4+ above) by 2030, with a full understanding of how each of the steps above is carried out and by whom. Publishers can play a vital role in enhancing the quality of published data. The team at Springer Nature, for example, are leading the way with their research data support service. We hope to see more publishers taking on the role of data stewards, and at Figshare we are happy to help advise any publisher taking their first steps into this new realm.
References
- Wilkinson, M., Dumontier, M., Aalbersberg, I. et al. The FAIR Guiding Principles for scientific data management and stewardship. Sci Data 3, 160018 (2016). https://doi.org/10.1038/sdata.2016.18
- Science, Digital; Fane, Briony; Ayris, Paul; Hahnel, Mark; Hrynaszkiewicz, Iain; Baynes, Grace; et al. (2019): The State of Open Data Report 2019. figshare. Report. https://doi.org/10.6084/m9.figshare.9980783.v2
- Nature 578, 199-200 (2020) https://doi.org/10.1038/d41586-020-00287-y
- Nature 578, 491 (2020) https://doi.org/10.1038/d41586-020-00505-7