

Our second event, "AI as Discovery Layer: On-Platform Tools That Transform How Users Find Content," took that question and grounded it in the decisions publishers are actively making right now — how to build on-platform AI discovery tools, how to balance reach with trust, and how to measure any of it when the frameworks we've relied on are still catching up to the technology.
I moderated a conversation with three panelists: Cheryl Firestone, Senior Manager of Publishing at the American Academy of Pediatrics; Tanya Laplante, Director of Product Platforms at Oxford University Press; and Tasha Mellins-Cohen, Executive Director at COUNTER Metrics. Watch the recording or read the recap below.
Setting the stage
The event kicked off by gauging attendees' own journey with the poll, "What best describes your organization's current approach to on-site AI-powered discovery." Results revealed that 10% had launched on-site tool and another 14% were actively building and piloting various tools. The bulk of respondents, however, are not yet actively engaged with AI tools for on-site discovery, with 41% evaluating options and 35% in the "wait and see" phase. 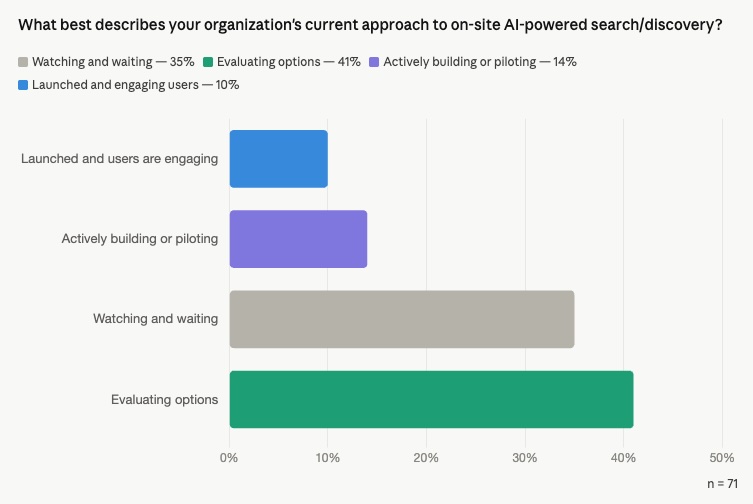
This position made hearing from speakers with hands-on experience all the more valuable, delivering real results, stats, and considerations for those early in their exploration.
The Problem Has Shifted
All three panelists agreed that the most significant change in recent years isn't the availability of new tools — it's that what researchers actually want from a discovery experience has fundamentally changed. They're no longer primarily searching for sources. They're searching for answers.As Tanya Laplante described it: "Before, users were trying to find content and sources. And they're still trying to find that, but more directly, they're trying to find answers to questions that they have." That shift has real implications for how publishers build discovery tools, because optimizing for keyword recall is a very different engineering and editorial problem from supporting natural language queries that expect synthesized, verified responses.
For the AAP, that change is visible in their own user research. A survey conducted ahead of the Red Book AI Assistant pilot found that 90% of users said they would be likely to use an AI tool on the site — so long as it only drew from the Red Book itself. Cheryl Firestone noted that framing carries significant weight: "Our users really trust the information that comes from the Academy, and they need to know that it's not hallucinating or getting information pulled in that's outside of our policies."
Tasha added the librarian community's perspective, which is increasingly focused on what happens when that trust breaks down. At UKSG earlier this year, her conversations centered on a pattern of students and faculty accepting AI-generated responses without verifying the source materials behind them. "It's a huge, huge question and source of debate in the library community at the moment — that trust and security and just basic research skills, they're being eroded by this reliance on an external brain."
On-Platform vs. Off-Platform
The panelists then considered whether they considered on-platform discovery and off-platform visibility to be competing or complementary strategies.Tanya described OUP's decision to open its free content layer to ChatGPT, Claude, and Perplexity, and the referral impact that followed. She shared that even as overall referral traffic declines — a trend consistent with what the industry is seeing broadly — average session duration on OUP's site has increased by roughly 30%. "What that suggests to us is that the users who are continuing to come to us are those really engaged researchers who might be getting an answer from ChatGPT, but are then saying to themselves, I need to go and look at the versions of record and the peer-reviewed content."
Tasha went further, pushing back on the idea that any of this is new: "Why is this so different from working with EBSCO, ProQuest, Web of Science, Scopus, ResearchGate, Google Scholar, or all the other places that we've been syndicating our content for, certainly as long as I've been in the industry? This is just a new type of syndication." She warned that publishers who aren't at the table now won't have the leverage to negotiate for usage visibility later. "I begged EBSCO and ProQuest and Elsevier and Clarivate to tell me what the usage was of my material on their discovery services, and I got zilch."
Trust as Competitive Advantage
If there was a through line to the whole conversation, it was trust — and the argument that in a world increasingly saturated with AI-generated content of uncertain provenance, scholarly publishers are in a stronger position than they often give themselves credit for.Tanya framed it as both an obligation and an opportunity: "AI, in some ways, is a threat to what we do, but also a real opportunity, because what we do is going to become more and more valued and premium and seen as the gold standard." That claim only holds, she noted, if publishers are investing in the tools and signals that actually demonstrate trustworthiness — not just asserting it.
Tasha went further, pointing to a public-good dimension that often gets overlooked in these conversations: "We can flood the zone with legitimate content. We can get the real information out there and combat things like vaccine disinformation in a way that simply hasn't been possible for the last couple of decades." For Cheryl's organization, that framing is quite literal — the Red Book AI Assistant is being built precisely because 67,000 AAP member pediatricians should have a trusted, evidence-based alternative to ChatGPT when they need clinical guidance. "If you're taking your child to your pediatrician, and they're using ChatGPT as a diagnosis tool," Cheryl said, "I'm frightened."
What the Data Tells Us
Tasha shared a preview of COUNTER's upcoming best practice guidance around reporting AI usage — the first COUNTER-compliant framework for reporting AI-driven usage alongside traditional human and text and data mining usage. The timing matters: publishers and libraries across six continents are watching their COUNTER usage decline even as raw traffic spikes with bot activity. "If you guys are seeing drops in your usage, it's not just you. Please don't panic."The new guidance would allow publishers to count AI-generated responses alongside the underlying content chunks they draw from, giving institutional subscribers a more complete picture of subscription value. It's a meaningful development — and one that reflects how quickly this space is moving. As Tasha noted, when COUNTER published their last release, ChatGPT had only been on the market for six months.
Tanya's implementation data from OUP offered concrete signals about on-site AI discovery tools. Traditional search currently drives click-through rates of around 9%. When users interact with OUP's AI discovery assistant and refine their queries through conversational follow-ups, that click-through rate climbs to 40% — a signal that the experience is getting users to content they actually want. "What it suggests is that as the user further refines the results via the chat function, those results become far more relevant to what they're looking for."
Implementation Considerations
Both Tanya and Cheryl had candid reflections on what the actual work of launching AI tools looks like — and where their assumptions didn't quite hold.For OUP, the most underestimated aspect wasn't technical. "Winning hearts and minds within your business is really critical," Tanya said, "and doing that same kind of campaigning with your customers and partners in that space, as well." Anything labeled AI — including tools that simply return improved search results, without any generative component — still requires extensive rounds of institutional review on the customer side. "The work around documentation, FAQs, seminars, and training our sales team was as much work as the technological lift of rolling out these tools."
For the AAP, the decision about where to start came down to identifying their highest-impact content and building from there. Cheryl described it as a deliberate choice: "When we decided to implement it, we went with one of our strongest pieces of content." The rationale was partly practical — the Red Book is heavily used, deeply trusted, and tightly scoped — and partly about laying infrastructure for expansion. "A lot of the work that's being done today is really laying the groundwork for future tools."
Looking Ahead
Asked what would need to be true for AI-powered discovery to expand readership rather than simply redistribute it, the panel converged on a few common threads. Machine readability came up repeatedly — Tasha made the point that optimizing content for AI agents and optimizing for accessibility share more in common than people tend to realize, and that publishers with poor metadata or missing alt text are already losing ground. "If you have content out there that doesn't have good metadata, you are wasting your most precious resource."Tanya returned to trust and visibility as the two things publishers need to hold simultaneously: investing in the markers that make content verifiably authoritative, while also being willing to meet researchers wherever their discovery journeys actually start. "It really does come back to trust and visibility in as many places as we can be visible."
The full recording of this session is available here. The series wraps up in May with an exploration of MCPs and other AI connectors — including what it means for discovery, usage, and the evolving relationship between publishers and AI agents. Register here to join us.